
このコンテンツはSEOmozの許可を受けて翻訳し再公表しています。
SEOmoz https://moz.com/beginners-guide-to-seo/how-search-engines-operate(2015.12.18)

検索エンジンは大きく2つの機能があります。クロールとインデックスを構築をすること、検索ユーザーに向けて検索エンジンが決めた最も関連のあるウェブサイトの順位リストを提供することです。
クロールとインデックス
ワールドワイドウェブ(www)上にある数十億の文書、ページ、ファイル、ニュース、ビデオ、メディアをクロールおよびインデックスすること
答えを提供すること
ユーザーのクエリ(疑問)に対する答えやユーザーが頻繁に検索し関連性にもとづいて順位づけされた関連ページを提供すること
クロールとインデックスとは
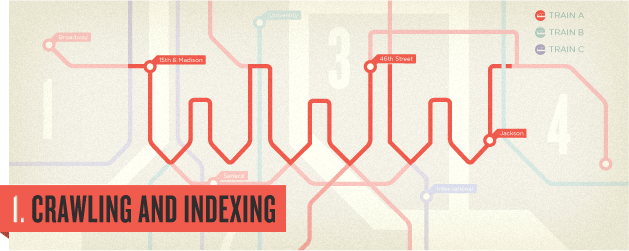
ワールドワイドウェブ(www)は大きな街にある地下鉄のようなネットワークだと想像してみてください
地下鉄の駅には独自の文書があって、多くはウェブページだけれどPDF、JPGなどもあります。
検索エンジンは線路に沿って「クロール」という方法を使って街に入ったりすべての駅をみつける必要があります。そして検索エンジンは利用できる最良な道を使いますーそれはリンクです。
ウェブでのリンク構築はすべてのページをともに結びつけます
リンクは「クローラー」や「スパイダー」と呼ばれる検索エンジンの自動ロボットによってウェブ上にある数十億もの互いにつながったドキュメントに届くようにします。
一度検索エンジンがこれらのページを見つけたら、ページにあるコードを判読し、巨大なデータベースから選ばれた部分を収納して、検索クエリへ答えを返すときが来たらふたたび呼び出されます。
数十億ものページを持つという重要なタスクを成し遂げることですぐにアクセスすることができ、検索エンジンの企業は世界中でデータセンターを構築しています。
これらの巨大な保管装置は大量の情報をすぐに処理する機械を数千個も持っています。
メジャーな検索エンジンで検索をしたとき、人々はすぐに結果を求めます。たとえ1,2秒の遅れさえも不満の原因になります。だから検索エンジンは可能な限り速く答えを提供するために必死で働いています。
答えを提供することとは

検索エンジンは答える機械です。人がオンライン検索をしたとき、検索エンジンは数十億もの資料から探し回ります。そして2つのことをします。
- 関連するものや検索者の疑問に便利な答えをただ返す
- ウェブサイトが提供している情報の人気によって順位付けする
SEOのプロセスとなる関連性と人気は影響力を意味します。
検索エンジンの関連性と人気を判断方法とは?
検索エンジンにとって関連性は正しいワードがあるページをより多く見つけることです。
近年のウェブでは、検索エンジンはこのような単純なステップで働かなくなっています。そして検索結果は限られた価値になってしまうのが現状です。
数年にわたって、スマートなエンジニアたちは検索者のクエリへの結果として合う方法を工夫してきました。今日では数百もの要因が関連性に影響していると言われています。
検索エンジンは一般的にサイトやページ、文書に人気があればあるほどより価値のある情報が含まれているとみなします。この仮定はユーザーの満足度という点でかなり成功してきました。
人気や関連性は手動で判断されていません。その代わりに検索エンジンは数学的な方程式(アルゴリズム)を使って価値のあるものとないものに分けていて(関連性)、そして品質によって順位づけしています(人気)。
これらのアルゴリズムは数百もの変化しやすい特徴を含んでいると言われています。検索マーケティングの領域ではわたしたちはそれらを「ランキング要因」と呼んでいます。わたしたちはこの検索エンジンランキング要因の資源を作りました。
検索エンジンの結果を読み続ける

検索エンジンが「大学(Universities)」というクエリでは、オハイオ州(Ohio State)が最も関連と人気があってハーバード(Harvard)はより少ない関連・人気だと信じていると推測することができます。
検索エンジンが提供するガイドライン
検索エンジンの複雑なアルゴリズムは理解できないようにみえるかもしれません。実際は検索エンジン自身はよいより結果を得たりトラフィックをより集めるためのインサイト(洞察)を少しだけ提供しています。
以下に検索エンジンがわたしたちに提供している最適化やベストな事例を示しています。

GoogleウェブマスターガイドラインのGoogleSEO情報
Googleは検索エンジンでよりよい順位を得るために次のことをすすめています。
- 検索エンジンではなくユーザーにとって第一となるページを作ること。あなたのユーザーをだましたりユーザーに表示しているコンテンツとは異なるものを検索エンジンに見せたりすつことを一般的に「クローキング」と言います。
- 明確な階層やテキストリンクのあるサイトを作ること。すべてページは少なくとも1つの
固定的なテキストリンクからリーチできるようにするべきです。 - 使いやすくて情報豊富なサイトを作り、明確で正確なコンテンツを記述したページにすること。
- あなたのtitle要素やALT属性がよく記述されていて正確であること。
- 記述的で創造されたキーワードを使い、ユーザーが見やすいURLを使うこと。文書にアクセスするための1つのURLを提供すること。301リダイレクトを使うか「rel=”canonical”」属性を複製されたコンテンツへ用いること。

BingウェブマスターガイドラインからのBingSEO情報
マイクロソフトのBingエンジニアは検索エンジンでよりよい順位を得るために次のことをすすめています。
- クリーンでキーワードが豊富なURL構造があること。
- コンテンツはリッチメディア(Adobe Flash Player, JavaScript, Ajax) を内部に隠していないか、リッチメディアがクローラーからリンクを隠していないか確かめること。
- キーワード豊富なコンテンツを作り、ユーザーが検索するキーワードに合うこと。定期的に新しいコンテンツを提供すること。
- 画像の中にインデックスしてほしいテキストを置かないこと。たとえばあなたの会社の名前や住所をインデックスされたかったら、会社のロゴの中に表示していないことを確実にする。
検索エンジンはウェブマスターの味方
この無料で提供しているアドバイスに加えて15年以上ウェブ検索は存在していて、検索マーケターたちは検索エンジンの順位のつけ方についての情報を得るメソッドを見つけてきました。
SEOそしてマーケターはサイトやサイトのクライアントがよりよい位置を勝ち取ることを助けるためのデータを使います。
驚くことに表立って見えていないけれど検索エンジンはこれらの努力を支援しています。
検索マーケティングの会議(たとえばthe Search Marketing Expo, Pubcon, Search Engine Strategies, Distilled, and MozCon)はエンジニアやすべての大手の検索エンジンの代表を招いています。
検索エンジンの代表者もブログやフォーラム、グループに参加しているウェブマスターを助けています。
ひょっとするとウェブマスターが検索エンジン自体を自由に使って実験し、仮説をテストし、見解を作ること以上に検索エンジンのアクティビティをリサーチできる素晴らしいツールはないかもしれません。
この対話を通して時々苦心しながら検索エンジンの機能によって拾い集められたかなりの量の知識を得ます。
たとえば以下のように実践してみます
- センスのないキーワードで新しいウェブサイトを登録する(ふとんがふっとんだ.comなど)。
- ウェブサイトにすべて似たようなおかしな表現をターゲットにして複数ページを作る。
- ページをできるだけ同じように作り、時間・テキストの配置・書式・使用するキーワード・リンク構築など一つだけ変える。
- インデックスされたドメインやほかのドメインでよくクロールされたページにリンクを貼る。
- 検索エンジンでページ順位を記録する。
- ページに小さな変更を作り、かすかに現れた変化に対してどの要因が結果に影響したのか検索結果で評価する。
- 効果的に現れた結果を記録しそれらをほかのドメインやほかの表現で再テストする。もしいくつかのテストが矛盾なく同じ結果を出したら、あなたが発見したパターンが検索エンジンで使われているかもしれません。
わたしたちが行ったテストの例
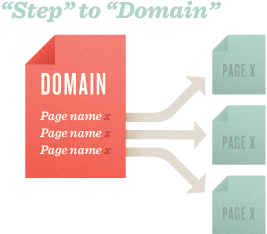
わたしたちのテストはページでの下位のリンク(a link lower)より上位のリンク(a link earlier)のほうが重要という仮説から始まりました。
わたしたちはセンスのないドメインを作り、すべて同じ単語が表示されている3つのリモートページのリンクをホームページに貼りテストしました。
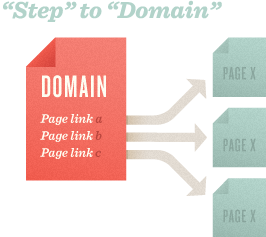
検索エンジンがページをクロールしたあと、わたしたちはホームページに上位のリンク(a link earlier)のあるページが1位に順位付けされているのを見つけました。
この過程は役に立ち検索マーケターの訓練を助けるだけではありません。
このようなテストを通して、検索マーケターは大手の検索エンジンによって作られたアメリカの特許庁への志願者を通して検索エンジンの働きについて競合する優れた人を集めることができます。
これらの中で1番有名なのは1990年代後半Googleのもとであるスタンフォード寄宿舎で文書で証明された特許番号#6285999「データベースに繋がったノードランキングのためのメソッド(Method for node ranking in a linked database.)」のページランクというシステムです。
このテーマのオリジナル論文「大規模なハイパーテキストのウェブ検索エンジンの分析」はかなり大きな研究テーマとなっています。
しかし心配する必要はありません。あなたは引き下がる必要はなく、SEOを実践するための補習的なレッスンをしていきましょう。
特許分析、実験、テストのような方法を通してコミュニティとしての検索マーケターは検索エンジンの多くの基礎的なオペレーションや高い順位と重大なトラフィックを得るウェブサイトやページを作るために不可欠な部分を理解してきました。
このガイドの残りの章はこれらの洞察をはっきりさせることに専念しています。ぜひ最後まで楽しんで!
- 検索エンジンの機能とは
- ユーザーの検索行動を知ろう
- 検索エンジンマーケティングはなぜ必要?
- 検索エンジンに強いサイトがしているSEOとは
- キーワード検索方法
- 検索順位を上げるユーザー体験
- 人気を集めるためのリンク構築
- SEOツールとサービス
- SEOと検索エンジンのよくある誤解
- 測定と追跡のSEO戦略
サイト名:SEOmoz
SEOmoz https://moz.com/beginners-guide-to-seo/how-search-engines-operate(2015.12.18)
※旧記事を翻訳して公開しています
このコンテンツはSEOmozの許可を受けて翻訳し再公表しています。版元SEOmozは弊サイトと提携しアフィリエイトを行っていません。This content was re-published with permission. SEOmoz is not affiliated with this site.





