
このコンテンツはSEOmozの許可を受けて翻訳し再公表しています。
SEOmoz https://moz.com/beginners-guide-to-seo/basics-of-search-engine-friendly-design-and-development(2015.12.18)

検索エンジンはウェブをクロールしコ
このガイドをプログラマーや情報制作者、デザイナーとシェアして

目次
インデックスされるためのSEO
検索エンジンの一覧でよりよく機能するために、最も重要なコンテン
インデックスされるために一番簡単な方法はHTMLテキストをページに置くことで訪問者に
インデックスされるためSEO
- 画像にaltテキストを追加…gif、jpg、png形式
の画像に視覚コンテンツのテキスト記述をHTMLの「alt属性 」を指定して検索エンジンに分かるようにする - 検索ボックス…ナビゲーションとクロールできるリンクのある検索ボックスを使う
- FlashやJavaプラグイン…ページ上にテキストが表示されるプラグインを使う
- 動画や音声コンテンツの文字起こしを提供する…言葉やフレーズが使われていたら検索エンジンにイン
デックスされるようにする
検索エンジンと同じ目線でサイトを見る
多くのウェブサイトはインデックスできるコンテンツに重大な問題
このページのGoogleテキストキャッシュをみて違いをみてみ
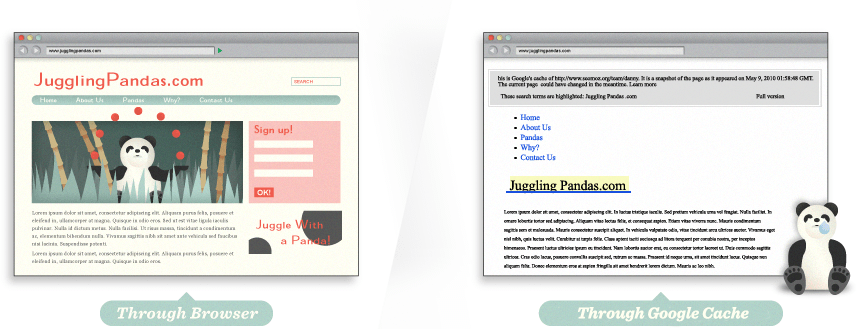
Googleキャッシュ機能を使うと、検索エ
コンテンツの楽しさはどこへ消えた?
Googleキャッシュを通すとページはまるで不毛地帯です。
斧を持って戦うサルが含まれているページは右のようなテキストでは不十分ですよね。
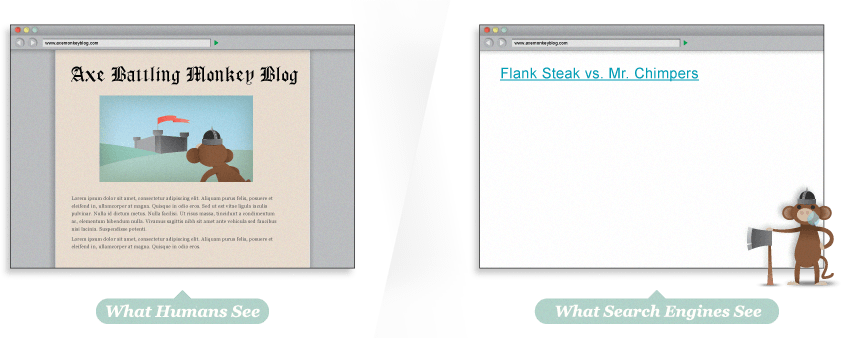
このサイトはすべてFlashで作られていますが、検索エンジン
HTMLテキストがないとこのページは検索結果の順位に現れるの
クロールできるリンク構造とは
クローラーがウェブサイトをあちこち見るための「クロールできるリンク構造」はウェブサイトのすべてのページを見つけ出すために必要です。
重大なミスのあるリンク構造をした多くのサイトは検索エンジンがアクセスできず、検索エンジンのインデックスに
ではどうして重大なミスが起きてしまうのか説明していきます。

GoogleのクローラーはAページに届いていてBとEページの
これはCとDのページに直接クロールできるリンク地点がないから

リンクタグは画像、テキストやその他オブジェクトなどページ上で
これらのリンクはインターネットのオリジナルナビゲーション要素で「ハイパ
上のイラストの”<a”タグはリンクの始まりを表しています。リンクの参照場所
この例ではURLのhttp://www.jonwye.comが参照され
リンクされたページはJon Wyeによって作られたベルトのページで“Jon Wye’s Custom Designed Belts.” がアンカーテキ
</a>タグでタグ部分とページ上のその他の要素を含んで
これは最も一般的なリンクの形式で検索エンジンが理解しやすいです。
クローラーは検索エンジンのリンクグラフへこの形式のリンクを追
クローラーがページへ届かない7つの理由
rel=”nofollow”リンク属性とは
rel=”nofollow” は以下の構文法によって使うことができます。
<a href=”https://moz.com” rel=”nofollow”>Lousy Punks!</a>
リンクは多くの属性を持つことができます。検索エンジンは重要な除外であるrel=”nofollow”属性のほぼすべてを無視します。
nofollowは検索エンジンにリンクをフォローしないように教えます(それ以外の働きもあります)。今までは自動のブログコメント、ゲストブック、リンクスパムを止める方法として使われてきました。
しかし検索エンジンにリンクの価値を減らす方法として時を経て姿を変えました。nofollowが付けられたリンクは検索エンジンによってわずかに違う判断をされます。しかし通常のリンクと同じように扱わないことは明確です。
nofollowリンクは悪い?
フォローされているリンクと同じ価値にはならないけれど、nofollowされたリンクは多様なリンクの側面の一部です。
バックリンクのあるウェブサイトはnofollowされたリンクを数多く蓄積していきますがこれは悪いことではありません。
実際にMozのランキング要因は高順位のサイトがそれ以外のサイトよりもnofollowのバックリンクを得ているという傾向が見られました。
Googleは多くの場合、nofollowリンクをフォローしないまたはこれらのリンクがページランクやアンカーテキストの価値を動かさないと主張しています。
nofollowリンクを使うことはGoogleにターゲットリンクを落とさせます。
nofollowリンクは価値を持たずリンクは存在していないHTMLテキストとして判断されます。
多くのウェブマスターはWikipediaのような権威あるサイトからのnofollowリンクは真実のしるしと判断されるだろうと思っています。
Bing
Bingはリンクグラフにnofollowリンクを含まないと主張していました。けれども未だにクローラーはnofollowリンクを新しいページを見つける方法として使っている可能性があります。
キーワードのSEO
実際に情報検索の技術全体(Googleのようなウェブベースの検索エンジンを含む)はキーワードが基礎になっています。
検索エンジンがページのコンテンツをクロールやインデックスすると、データベースで公開されている250億ものウェブページよりもキーワードベースのインデックスページを追跡し続けます。
数百万かそれ以下の小さいデータべースはそれぞれ特定のキーワード用語やフレーズを中心に置いて、検索エンジンにほんの数秒で必要なデータを検索させます。
もしあなたが「犬」の検索結果でページ順位付けするチャンスを得たかったら、「犬」という単語をクロールできるコンテンツの文書の一部に入れることをおすすめします。
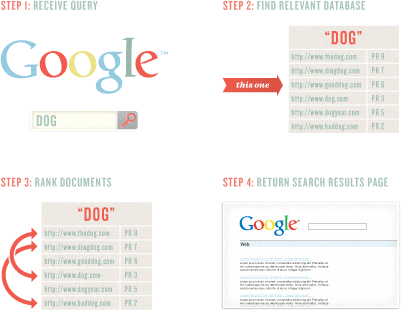
キーワードの支配
わたしたちが検索するために単語を入力するとき、検索エンジンは入力した単語をベースに検索し合致するページを提供します。
単語の順番(“pandas juggling”か”juggling pandas”)や文字の種類は検索エンジンが正しいページの検索を助けて順位付けするための追加情報となります。
検索エンジンはどのキーワードが質問への助けとなる関連ページで使われているのか測定しています。
キーワードをより具体的にすればするほど検索結果での競合が少なくなります。そして良い順位を勝ち取るチャンスが訪れます。

この地図のイラストは広い単語の「本」と特定の単語である本のタイトル「Tale of Two Cities」を比べています。
広い単語では多くの検索結果が得られる一方、特定の単語での検索結果はかなり少ないけれど競合も少ないということが言えます。
キーワードの乱用
オンライン検索が始まって以来、ウェブ界隈は検索エンジンを操作するための惑わすキーワードを乱用してきました。
近年、検索エンジンは実際どのようにキーワードが使われているかに関わらず関連性の信号としてキーワードの使用状況を見ています。
検索エンジンはまだ人間と同じようにテキストを読解し見抜けないけれども、学習によって人間に近づいてきています。
あるページが「エッフェル塔」というキーワードを狙っているならエッフェル塔についてのコンテンツの中に塔の歴史やパリのおすすめホテルを自然と含めるでしょう。
一方で単純に「エッフェル塔」という単語を関連のないコンテンツページにばらまいたら、エッフェル塔での順位付けは長い道のりになってしまいます。
ページ上の最適化
キーワードの使用とねらいは検索エンジンのランキングアルゴリズムの一部になっていて、最適化されたページの作成を助けるために効果的なキーワードの技術を利用することができます。
Mozではキーワードの使用戦略をベースに多くのテストを重ねて検索結果と変化を見てきました。
あなたのサイトでぜひ試してほしいプロセスは以下の通りです。
キーワードフレーズの使い方
- タイトルタグでキーワードを少なくとも1回入れる。キーワードフレーズを可能な限りタイトルタグの近くに入れ続ける。タイトルタグの詳細はこの章の後半でお伝えする。
- ページの上部で目立つところにキーワードを1回入れる。
- リード文にキーワードが変化したものを含めて少なくとも2~3回入れる。テキストコンテンツが多くあったらもう少し多くキーワードを入れる。きっとあなたはキーワードの使用や変化についてより価値を見つけるけれど、わたしたちの経験で言うとより実例が増えた言葉やフレーズはランキングで効果がなくなる傾向になっている。
- ページ上の画像のalt属性に少なくとも1回キーワードを入れる。これはウェブ検索を助けるためだけでなく画像検索によって価値のあるトラフィックを獲得する機会を得ることができる。
- URLにキーワードを一回入れる。URLとキーワードのルールはこの章の後半で紹介する。
- メタディスクリプションタグに少なくとも1回キーワードを入れる。メタディスクリプションタグはランキングのための検索エンジンに慣れているわけではないが、検索結果ページを読んだ検索者にクリックされやすくなる。メタディスクリプションは検索エンジンにテキストスニペットとして使われるようになる。
- サイトの別ページへのリンクアンカーテキストにキーワードを使うべきではない。これはキーワードカニバリゼーションとして知られている。
キーワード密度という迷信
キーワード密度は近年のランキングアルゴリズムの一部ではないとDr.エデル・ガルシアさんがThe Keyword Density of Non-Senseで論証しています。
D1とD2という2つの文章があって1000の言葉(l = 1000)と20回繰り返された言葉(tf = 20)が含まれているとします。キーワード密度の分析者は2つの文書のキーワード密度は[Keyword Density (KD) KD = 20/1000 = 0.020 (or 2%) ]とあなたに伝えるでしょう。
tf = 10 かつ l = 500のとき全く同じ価値になります。明らかにキーワード密度分析者はどちらの文書がより関連しているのかを立証することはできていません。
密度分析やキーワード密度の割合は私たちに以下のことを教えてはくれません。
- 文章中のキーワードとその関連性との距離感(近接性)
- 文章における言葉の存在地点(配分)
- 言葉間の相互サイテーション頻度(相互発生)
- 文書のメインテーマ、トピック、サブトピック
結論:キーワード密度はコンテンツ・質・意味・関連性から分離されています。
最適化ページ密度はこうなるべき?「Running Shoes」という言葉で最適化ページはこのようになると考えられます。

タイトルタグのSEO
タイトルタグは検索エンジン最適化の重要な部分です。以下の最良な例はタイトルタグ作成は簡単に達成できるすばらしいSEO対策です。
検索エンジンとユーザビリティへのタイトルタグ最適化
①タイトルの長さを意識する
検索エンジンは英語ならタイトルタグの始めの65~75字を検索結果に表示します。そのあとに検索エンジンは”…”と省略します。
これは多くのソーシャルメディアサイトでの一般的な制限と同じで広く見られます。
しかし複数のキーワードや長いキーワードフレーズを狙ったとしたとしても、タイトルタグは適切に長くなったと判断されて基本的に順位付けされていています。
②重要なキーワードは始まりの近くに置く
キーワードをタイトルタグの始まり近くに置くことでキーワードを順位付けすることをより助け、検索結果でユーザーがよりクリックするようになるでしょう。
③ブランディングを含める
Mozではブランドへの気づきを増やすためにすべてのタイトルタグの最後にブランド名の言及をするようにしています。これによってそのブランドに親しみのある人々へ高いクリックスルー率を生み出します。
ホームページの場合、あなたのブランド名をタイトルタグの始めに置くことが理解できるでしょう。タイトルタグの始まりの言葉がより重要になって以来、順位付けのために気にかけるといいです。
④読みやすさと感情的なインパクトを考える
タイトルタグは説明的で読みやすいものにするべきです。
タイトルタグは新しい訪問者とあなたのブランドと最初のやりとりになります。タイトルタグは可能な限り良い印象を与えるべきです。
影響力のあるタイトルタグは検索結果で人々の注目を集め、あなたのサイトへより多くの訪問者を呼び込みます。
このSEO対策は最適化やキーワード戦略だけではなくてユーザー体験全体を指しています。
タイトルタグはインターネットブラウジングソフトウェアの上部に現れ、コンテンツがソーシャルメディアでシェアされたり再発表されたときに記事タイトルとして使われます。
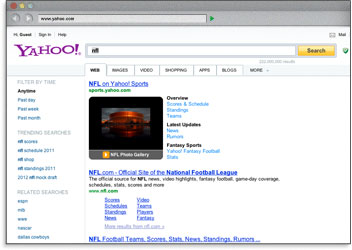
タイトルタグでキーワードを使うことはユーザーがそのキーワードをクエリとして使ったときの検索結果で検索エンジンがその言葉を強調することを意味しています。これはサイトの露出やクリックスルー率がを多く獲得することにつながります。
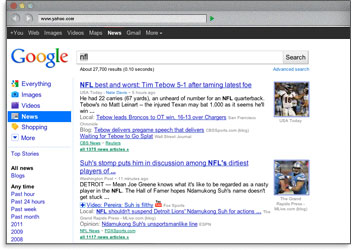
記述的でキーワードの入ったタイトルタグを作る一番の理由は検索エンジンで順位付けされるためです。
半年ごとに行うMozによるSEO業界のリーダーたちに調査があります。
メタタグのSEO
メタロボットとは
メタロボットタグによってページごとに検索エンジンクローラーのアクティビティを操作しやすくなります。(メジャーな検索エンジンすべてに適用します)
メタロボットは検索エンジンがページをどう捉えるかをコントロールすることができます。
メタディスクリプションとは
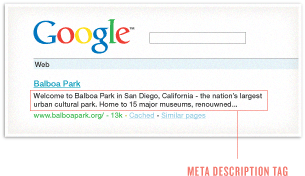
メタディスクリプションタグはコンテンツの短い記述部分として存在しています。
検索エンジンは順位付けのためにこのタグにあるキーワードやフレーズを使いません。しかしメタディスクリプションは検索結果のリストの真下に表示されるテキストスニペットのための最初の情報源です。
読むことのできる文章を作り重要なキーワードをぎゅっと詰め込むことでより高いクリックスルー率を得ることができます。記述の中でGoogleが検索キーワードをどのように強調するか注目してください。
メタディスクリプションはどんな長さも可能ですが検索エンジンはスニペットを英語なら160字以下に切り取ってしまうので一般的にこのような文字数に留めておくのがいいでしょう。(翻訳者注:日本語のスニペットは130文字程度)
メタディスクリプションが欠落しているときは、検索エンジンはページの要素から検索スニペットを作り出します。
多数キーワードやトピックをターゲットにしたページのためにはメタディスクリプションはとても効果的な戦略です。
重要ではないメタタグ
メタキーワード:メタキーワードタタグは一度は効果がありましたがもはやSEOでは重要とは言えません。どうしてメタキーワードの使用をやめることになったのかという歴史SearchEngineLandのMeta Keywords Tag 101を読んでみてください。
Meta Refresh, Meta Revisit-after, Meta Content-typeなど: これらのタグはSEOのために使用できるけれど重要では無くなってきています。くわしくはGoogle がサポートしているメタタグに譲ります。
URL構造とは
URLとはWEB上にある文書の住所であり検索の視点ですばらしい価値があります。URLは複数の重要な場所に現れます。

検索エンジンが検索結果にURLを表示したとき、クリックスルーや露出にインパクトを与えることができます。URLは順位付けされた文書に使われ、検索クエリにある単語を含んだページはそのキーワードを使うことで利益を得ることがあります。

ブラウザのアドレスバーに表示されたURLは検索エンジンにはほとんど影響がない一方で脈略のないURL構造やデザインはユーザー体験を損なうことになります。

上記のURLはアンカーテキストでこの記事の参考ページを指すことに使われています。
URL構築ガイドライン
正規コンテンツと複製コンテンツ
このように「正規化」することは異なるURLで2つやそれ以上のウェブページが表れたときに起こります。
これは近代的なコンテンツマネジメントシステムではとても一般的です。例えば通常ページと印刷版ページを提示するかもしれません。
複製コンテンツは多数のウェブサイトで現すこともできますが検索エンジンで大きな問題が存在してしまいます。
一体コンテンツのどのバージョンを検索者に表示させるべきなのか?SEOコミュニティではこの問題を複製コンテンツとして言及しています(参考:Duplicate contents)


正規化はあなたのコンテンツに構造を与える実践です。正規コンテンツはたった一つしかない唯一のURLであるという方法です。
もしウェブサイトに同じコンテンツが多数あったらどれがが正しいか分からなくなってしまいます。

その代わりにサイトオーナーが3つのページを301リダイレクトすると検索エンジンはサイトからたった一つの強いページをリストに存在させます。
良く順位付けされる可能性のある多数のページを1つのページに結合させたら、それぞれ競合するのを止めるだけではなくて全体的に強い関連性や人気度の信号を生み出します。
これは検索エンジンにおいて良い順位付けに働くことになります。
正規タグで救出する
Canonial URL Tagと呼ばれる検索エンジンとは異なるオプションによって1つのサイトにある複製コンテンツの実例を減らして固有のURLとして正規化します。
これは異なるウェブサイトでも使うことができ、1つのドメインの1つのURLから異なるドメインの異なるURLまで使えます。
複製コンテンツを含むページでCanonial URLタグを使います。このタグは順位付けしたい唯一のURLに使います。
<link rel=”canonical” href=”https://moz.com/blog”/>
このようなタグは検索エンジンにこのページをhttps://moz.com/blogというURLのコピーとして扱い検索エンジンが用いたすべてのリンクやコンテンツはこのURLが正規ページだと知らせています。
SEOの視点からCanonical URLタグ属性は301リダイレクトに似ています。
301のように多数のページを一つだと認識させるために検索エンジンに教えているのであって実際に訪問者を新しいURLへリダイレクトするわけではありません。
※翻訳者注:重複したURLを統合する(Google)
リッチリザルトとは
リッチリザルトは構造化データの一つでウェブマスターに検索エンジンへ情報を提供する方法としてコンテンツを書き加えることを許可しています。
リッチリザルトや構造化データの使用は検索エンジンフレンドリーなデザインとしての要素を求めていませんがそのような適応能力はあらゆる環境でアドバンテージを得るウェブマスターということを意味します。
構造化データは検索エンジンがコンテンツがどんな種類なのかを簡単に認識できるようにコンテンツに指定を加えることを意味します。
Schema.orgは構造化された人々・商品・レビュー・ビジネス・レシピ・イベントなどの指定データの例を提供しています。
Schema.org、GoogleのRich Snippet Testing Tool、MozBarなどリッチリザルトを学ぶためのあらゆる良いリソースがあります。
※翻訳者注:構造化データ機能を選択する(Google)
リッチリザルトの実例
あなたのブログでSEO会議について知らせてみましょう。通常のHTMLでコードはこのようになっているとします。
<div>
SEO Conference<br/>
Learn about SEO from experts in the field.<br/>
Event date:<br/>
May 8, 7:30pm
</div>
ここで私たちは構造化データで検索エンジンへより特定のデータの種類について情報を知らせることができます。
最終的には以下のようになります。
<div itemscope itemtype=”http://schema.org/Ev
<div itemprop=”name”>SEO Conference</div>
<span itemprop=”description”>Learn about SEO from experts in the field.</span>
Event date:
<time itemprop=”startDate” datetime=”2012-05-08T19:30″>Ma
</div>
サイトの信用を守るには
順位を奪おうとする複製サイトへの対策
ウェブは自らのドメインにほかのサイトからコンテンツを抜き取ったり再利用するビジネスやトラフィックモデルをした不道徳なウェブサイトによって散らかされています。
もしRSSやXMLのような形式のコンテンツを公開したら、大規模なブログやトラッキングサービス(Google、Technorati、Yahoo!など)に必ず知らせましょう。
サイトから直接GoogleやTechnoratiのようなサービスに知らせたり、Pingomaticのような自動で手続きするサービスを使って知らせることができます。
※翻訳者注:更新通知サービス – WordPress Codex 日本語版
そこで記事にあなたのサイトへのバックリンクを含めることで、あなたが書いた記事を特定し検索エンジンがあなたのリンクへ戻るコピーコンテンツが多いことが分かります。検索エンジンへあなたのソースがオリジナルだと示すのです。
このために内部リンク構造に関連リンクを使う必要があります。たとえばホームページへのリンクでは
<a href=”../”>Home</a>
ではなくて代わりに以下のようにリンクを使います。
<a href=”https://moz.com”>Home</a
この方法はスクラップする人がコンテンツをコピーし選んだときにリンクはあなたのサイトへ戻ります。
スクラップする人へより高度な対策はありますが、そればかりに苦心しているのは本末転倒です。あなたが人気で露出が多いサイトを手にした結果により、スクラップや再公開されたサイトを見つけるのです。
この複製コンテンツの問題を何度か無視することになるでしょう。しかしあまりにもひどい複製をされて、あなたの順位やトラフィックを抜いてしまったらデジタルミレニアム著作権法(DMCA)と呼ばれる法的な措置を考えましょう。
※翻訳者注:デジタルミレニアム著作権法 – Wikipedia
- 検索エンジンの機能とは
- ユーザーの検索行動を知ろう
- 検索エンジンマーケティングはなぜ必要?
- 検索エンジンに強いサイトがしているSEOとは
- キーワード価値調査
- 検索順位を上げるユーザー体験
- 人気を集めるためのリンク構築
- SEOツールとサービス
- SEOと検索エンジンのよくある誤解
- 測定と追跡のSEO戦略
このコンテンツはSEOmozの許可を受けて翻訳し再公表しています。
SEOmoz https://moz.com/beginners-guide-to-seo/basics-of-search-engine-friendly-design-and-development(2015.12.18)
このコンテンツはSEOmozの許可を受けて翻訳し再公表しています。版元SEOmozは弊サイトと提携しアフィリエイトを行っていません。This content was re-published with permission. SEOmoz is not affiliated with this site.





